大多数时候,我们在开发软件甚至使用软件时,都是在操作系统的安全范围内进行游戏。我们甚至不知道网络接口如何欢迎该 IP 数据包,也不知道当我们保存文件时文件系统如何处理这些 inode。
该边界称为 user space ,它是我们编写应用程序、库和工具的地方。但还有另一个世界,那就是 kernel space 。它是操作系统内核所在的位置,负责管理系统资源,例如内存、CPU 和 I/O 设备。
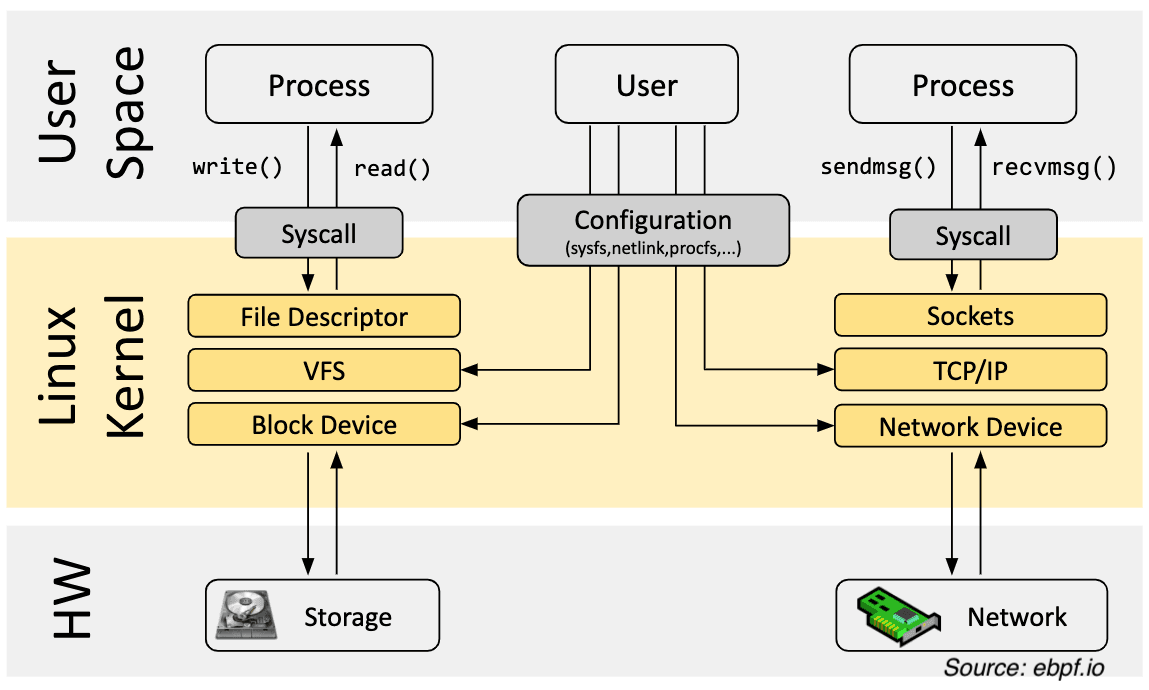
我们通常不需要低于套接字或文件描述符,但有时我们需要这样做。假设您想要分析一个应用程序以查看它消耗了多少资源。
如果从用户空间分析应用程序,您不仅会错过太多有用的细节,而且还会消耗大量资源来分析本身,因为 CPU 或内存之上的每一层都会引入一些开销。
需要更深入
假设您想要深入堆栈并以某种方式将自定义代码插入内核中以分析应用程序,或跟踪系统调用,或监视网络数据包。你会怎么做?
传统上你有两种选择。
选项 1:编辑内核源代码
如果您想要更改 Linux 内核源代码,然后将相同的内核发送到您客户的机器上,您需要说服 Linux 内核社区需要进行更改。然后,您将需要等待几年才能让新的内核版本被 Linux 发行版采用。
对于大多数情况来说,这不是一个实用的方法,而且也有点不实用。
仅用于分析应用程序或监视网络数据包。
选项 2: 写一个内核模块
你可以编写一个内核模块,它是一段可以加载到内核中并执行的代码。这是一种更实用的方法,但它也有其自身的风险和缺点。
首先,你需要编写一个内核模块,这不是一件容易的事。然后,你需要定期维护它,因为内核是一个有生命的东西,它会随着时间的推移而变化。如果您不维护内核模块,它将过时并且无法与新的内核版本一起使用。
其次,您面临着损坏 Linux 内核的风险,因为内核模块没有安全边界。如果您编写的内核模块有错误,则可能会导致整个系统崩溃。
选择 eBPF
eBPF(扩展伯克利数据包过滤器)是一项革命性技术,允许您在几分钟内重新编程 Linux 内核,甚至无需重新启动系统。
eBPF 允许您跟踪系统调用、用户空间函数、库函数、网络数据包等等。它是用于系统性能、监控、安全等方面的强大工具。
如何使用
eBPF 是一个由多个组件组成的系统:
- eBPF programs
- eBPF hooks
- BPF maps
- eBPF 验证器
- eBPF 虚拟机
请注意,我交替使用了术语“BPF”和“eBPF”。 eBPF 代表“扩展伯克利数据包过滤器”。 BPF 最初被引入 Linux 来过滤网络数据包,但 eBPF 扩展了原始 BPF,使其可以用于其他目的。今天它与伯克利无关,而且它不仅仅用于过滤数据包。
下面说明了 eBPF 如何在用户空间和底层工作。 eBPF 程序用高级语言(例如 C)编写,然后编译为 eBPF bytecode 。然后,eBPF 字节码被加载到内核中并由 eBPF virtual machine 执行。
eBPF 程序附加到内核中的特定代码路径,例如系统调用。这些代码路径称为 hooks 。当钩子被触发时,eBPF 程序就会被执行,现在它会执行您编写的自定义逻辑。这样我们就可以在内核空间中运行我们的自定义代码。
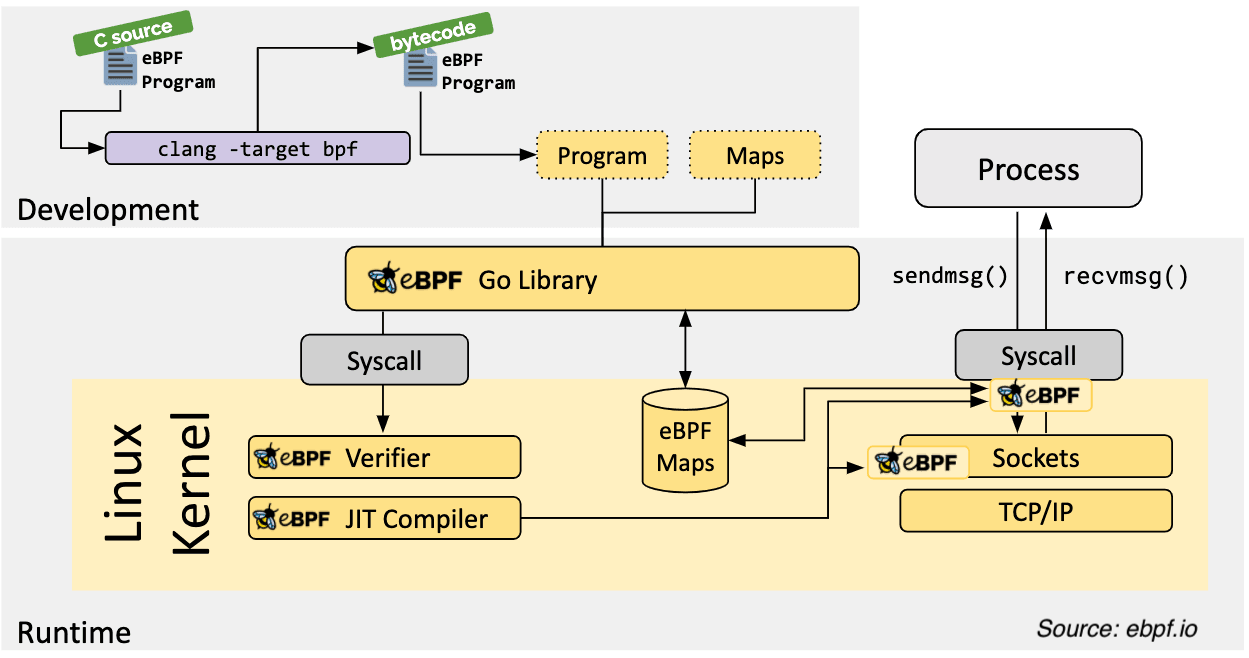
eBPF Hello World
在继续讨论细节之前,让我们编写一个简单的 eBPF 程序来跟踪 execve 系统调用。我们将用 C 编写程序,用 Go 编写用户空间程序,然后运行用户空间程序,将 eBPF 程序加载到内核中,并在实际的 < 之前轮询我们将从 eBPF 程序发出的自定义事件。 b1>系统调用被执行。
编写 eBPF 程序
我们先开始编写eBPF程序。我将逐部分编写以更好地解释细节,但您可以在我的 GitHub 存储库中找到整个程序: ozansz/intro-ebpf-with-go。
// hello_ebpf.c
1#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
struct event {
u32 pid;
u8 comm[100];
};
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 1000);
} events SEC(".maps");这里我们导入 vmlinux.h 头文件,它包含了内核的数据结构和函数原型。然后我们包含 bpf_helpers.h 头文件,其中包含 eBPF 程序的辅助函数。
然后我们定义一个 struct 来保存事件数据,然后定义一个 BPF map 来存储事件。我们将使用此Map在将在内核空间中运行的 eBPF 程序与用户空间程序之间传递事件。
稍后我们将详细介绍 BPF maps,因此,如果您不明白我们为什么使用
BPF_MAP_TYPE_RINGBUF或SEC(".maps")的用途,请不要担心。
我们现在准备编写第一个程序并定义它将附加到的钩子:
// hello_ebpf.c
SEC("kprobe/sys_execve")
int hello_execve(struct pt_regs *ctx) {
u64 id = bpf_get_current_pid_tgid();
pid_t pid = id >> 32;
pid_t tid = (u32)id;
if (pid != tid)
return 0;
struct event *e;
e = bpf_ringbuf_reserve(&events, sizeof(struct event), 0);
if (!e) {
return 0;
}
e->pid = pid;
bpf_get_current_comm(&e->comm, 100);
bpf_ringbuf_submit(e, 0);
return 0;
}这里我们定义了一个函数 hello_execve ,并使用 kprobe 钩子将其附加到 sys_execve 系统调用。 kprobe 是 eBPF 提供的众多钩子之一,用于跟踪内核函数。该钩子将在执行 sys_execve 系统调用之前触发我们的 hello_execve 函数。
在 hello_execve 函数中,我们首先获取进程ID和线程ID,然后检查它们是否相同。如果它们不相同,则意味着我们在一个线程中,并且我们不想跟踪线程,因此我们通过返回零来退出 eBPF 程序。
然后我们在 events Map中预留空间来存储事件数据,然后用进程ID和进程的命令名称填充事件数据。然后我们将事件提交到 events map。
到目前为止这很简单,对吧?
编写用户空间程序
在开始编写用户空间程序之前,我先简单解释一下程序在用户空间需要做什么。我们需要一个用户空间程序将 eBPF 程序加载到内核中,创建 BPF Map,附加到 BPF Map,然后从 BPF Map中读取事件。
为了执行这些操作,我们需要使用特定的系统调用。该系统调用称为 bpf() ,它用于执行一些与 eBPF 相关的操作,例如读取 BPF Map的内容。
我们也可以从用户空间自己调用这个系统调用,但这意味着太多的低级操作。值得庆幸的是,有一些库为 bpf() 系统调用提供了高级接口。其中之一是 Cilium的 ebpf-go 包,我们将在本示例中使用它。
让我们深入研究一些 Go 代码。
// main.go
//go:generate go run github.com/cilium/ebpf/cmd/bpf2go -type event ebpf hello_ebpf.c
func main() {
stopper := make(chan os.Signal, 1)
signal.Notify(stopper, os.Interrupt, syscall.SIGTERM)
// Allow the current process to lock memory for eBPF resources.
if err := rlimit.RemoveMemlock(); err != nil {
log.Fatal(err)
}
objs := ebpfObjects{}
if err := loadEbpfObjects(&objs, nil); err != nil {
log.Fatalf("loading objects: %v", err)
}
defer objs.Close()
kp, err := link.Kprobe(kprobeFunc, objs.HelloExecve, nil)
if err != nil {
log.Fatalf("opening kprobe: %s", err)
}
defer kp.Close()
rd, err := ringbuf.NewReader(objs.Events)
if err != nil {
log.Fatalf("opening ringbuf reader: %s", err)
}
defer rd.Close()
// ...第一行是 Go 编译器指令 go:generate。这里我们让 Go 编译器运行 github.com/cilium/ebpf/cmd/bpf2go 包中的 bpf2go 工具,并从 hello_ebpf.c 文件生成 Go 文件。
生成的 Go 文件将包括 eBPF 程序的 Go 表示、我们在 eBPF 程序中定义的类型和结构体等。然后我们将在 Go 代码中使用这些表示将 eBPF 程序加载到内核中,并进行交互与 BPF map。
然后我们使用生成的类型来加载eBPF程序(loadEbpfObjects),附加到kprobe钩子(link.Kprobe),并从BPFMap中读取事件(ringbuf.NewReader)。所有这些函数都使用了生成的类型。
是时候与内核侧交互了:
// main.go
// ...
go func() {
<-stopper
if err := rd.Close(); err != nil {
log.Fatalf("closing ringbuf reader: %s", err)
}
}()
log.Println("Waiting for events..")
var event ebpfEvent
for {
record, err := rd.Read()
if err != nil {
if errors.Is(err, ringbuf.ErrClosed) {
log.Println("Received signal, exiting..")
return
}
log.Printf("reading from reader: %s", err)
continue
}
if err := binary.Read(bytes.NewBuffer(record.RawSample), binary.LittleEndian, &event); err != nil {
log.Printf("parsing ringbuf event: %s", err)
continue
}
procName := unix.ByteSliceToString(event.Comm[:])
log.Printf("pid: %d\tcomm: %s\n", event.Pid, procName)
}
}我们启动一个 goroutine 来监听 stopper 通道,该通道是我们在前面的 Go 代码片段中定义的。当我们收到中断信号时,该通道将用于优雅地停止程序。
然后我们启动一个循环来从 BPF Map中读取事件。我们使用 ringbuf.Reader 类型来读取事件,然后使用 binary.Read 函数将事件数据解析为 ebpfEvent 类型,该类型由eBPF 程序。
然后我们将进程 ID 和进程的命令名称打印到标准输出。
运行程序
现在我们已经准备好运行该程序了。首先,我们需要编译eBPF程序,然后运行用户空间程序。
$ go generate
Compiled /Users/sazak/workspace/gocode/src/github.com/ozansz/intro-ebpf-with-go/0x01-helloworld/ebpf_bpfel.o
Stripped /Users/sazak/workspace/gocode/src/github.com/ozansz/intro-ebpf-with-go/0x01-helloworld/ebpf_bpfel.o
Wrote /Users/sazak/workspace/gocode/src/github.com/ozansz/intro-ebpf-with-go/0x01-helloworld/ebpf_bpfel.go
Compiled /Users/sazak/workspace/gocode/src/github.com/ozansz/intro-ebpf-with-go/0x01-helloworld/ebpf_bpfeb.o
Stripped /Users/sazak/workspace/gocode/src/github.com/ozansz/intro-ebpf-with-go/0x01-helloworld/ebpf_bpfeb.o
Wrote /Users/sazak/workspace/gocode/src/github.com/ozansz/intro-ebpf-with-go/0x01-helloworld/ebpf_bpfeb.go
$ go build -o hello_ebpf
我们首先运行 go generate 命令编译eBPF程序,然后运行 go build 命令编译用户空间程序。
然后我们运行用户空间程序:
sudo ./hello_ebpf
hello_ebpf: 01:20:54 Waiting for events..我在Lima的虚拟机内运行这个程序,为什么不打开另一个 shell 看看会发生什么?
limactl shell intro-ebpf
$同时在第一个 shell 中:
hello_ebpf: 01:22:22 pid: 3360 comm: sshd
hello_ebpf: 01:22:22 pid: 3360 comm: bash
hello_ebpf: 01:22:22 pid: 3361 comm: bash
hello_ebpf: 01:22:22 pid: 3362 comm: bash
hello_ebpf: 01:22:22 pid: 3363 comm: bash
hello_ebpf: 01:22:22 pid: 3366 comm: bash
hello_ebpf: 01:22:22 pid: 3367 comm: lesspipe
hello_ebpf: 01:22:22 pid: 3369 comm: lesspipe
hello_ebpf: 01:22:22 pid: 3370 comm: bash正如预期的那样,我们看到 sshd 进程正在启动,然后 bash 进程正在启动,然后 lesspipe 进程正在启动,依此类推。
这是一个简单的示例,说明我们如何使用 eBPF 跟踪 execve 系统调用,然后从用户空间的 BPF Map中读取事件。我们编写了一个相当简单但功能强大的程序,并且在不修改内核源代码或重新启动系统的情况下拦截了 execve 系统调用。
eBPF Hooks 和 Maps
那么,前面的示例中实际发生了什么?我们使用 kprobe 挂钩将 eBPF 程序附加到 sys_execve 系统调用,以便在 sys_execve 系统调用时运行 hello_execve 函数在执行原始系统调用代码之前调用。
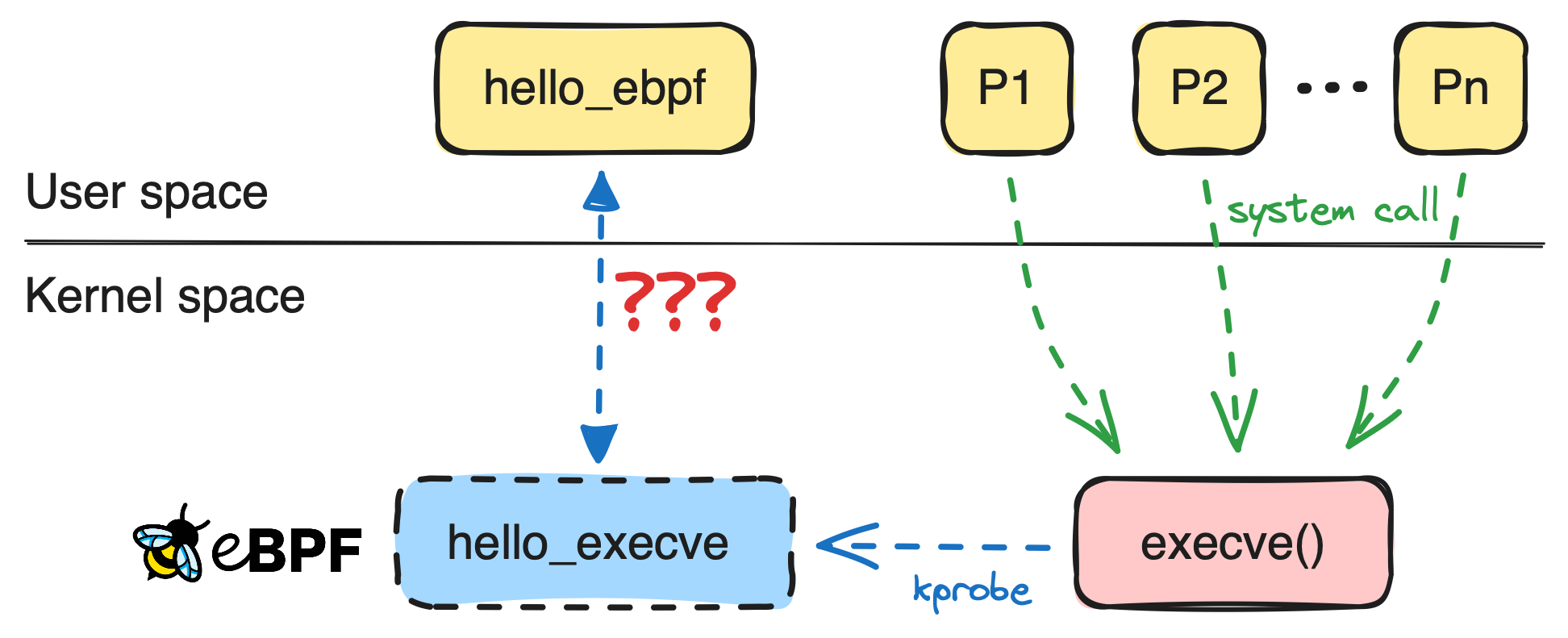
eBPF 是事件驱动的,这意味着它希望我们将 eBPF 程序附加到内核中的特定代码路径。这些代码路径称为“钩子”,eBPF 提供了多种类型的钩子。最常见的是:
kprobe,kretprobe: 跟踪内核函数uprobe,uretprobe: 跟踪用户空间函数tracepoint: 跟踪内核中预定义的跟踪点xdp: eXpress Data Path, 用于过滤和重定向网络数据包usdt: 用户静态定义的跟踪,用于以更有效的方式跟踪用户空间函数
钩子 kprobe 和 uprobe 用于在函数/系统调用执行之前调用附加的 eBPF 程序,并使用 kretprobe 和 uretprobe 在函数/系统调用执行之后调用附加的 eBPF 程序。
我们还使用 BPF Map来存储事件。 BPF Map是用于存储和通信不同类型数据的数据结构。我们还将它们用于状态管理。支持的 BPF Map类型太多,我们根据不同的目的使用不同类型的Map。一些最常见的 BPF Map类型是:
BPF_MAP_TYPE_HASH: 哈希表BPF_MAP_TYPE_ARRAY: 数组BPF_MAP_TYPE_RINGBUF: ring bufferBPF_MAP_TYPE_STACK: 栈BPF_MAP_TYPE_QUEUE: 队列BPF_MAP_TYPE_LRU_HASH: LRU hash map
其中一些Map类型还具有每个 CPU 的变体,例如 BPF_MAP_TYPE_PERCPU_HASH ,它是一个哈希Map,每个 CPU 核心都有一个单独的哈希表。
更进一步: 跟踪传入的 IP 数据包
让我们更进一步,编写一个更复杂的 eBPF 程序。这次,我们将在网络接口向内核发送网络数据包之后,甚至在内核处理该数据包之前,使用 XDP 钩子调用 eBPF 程序。
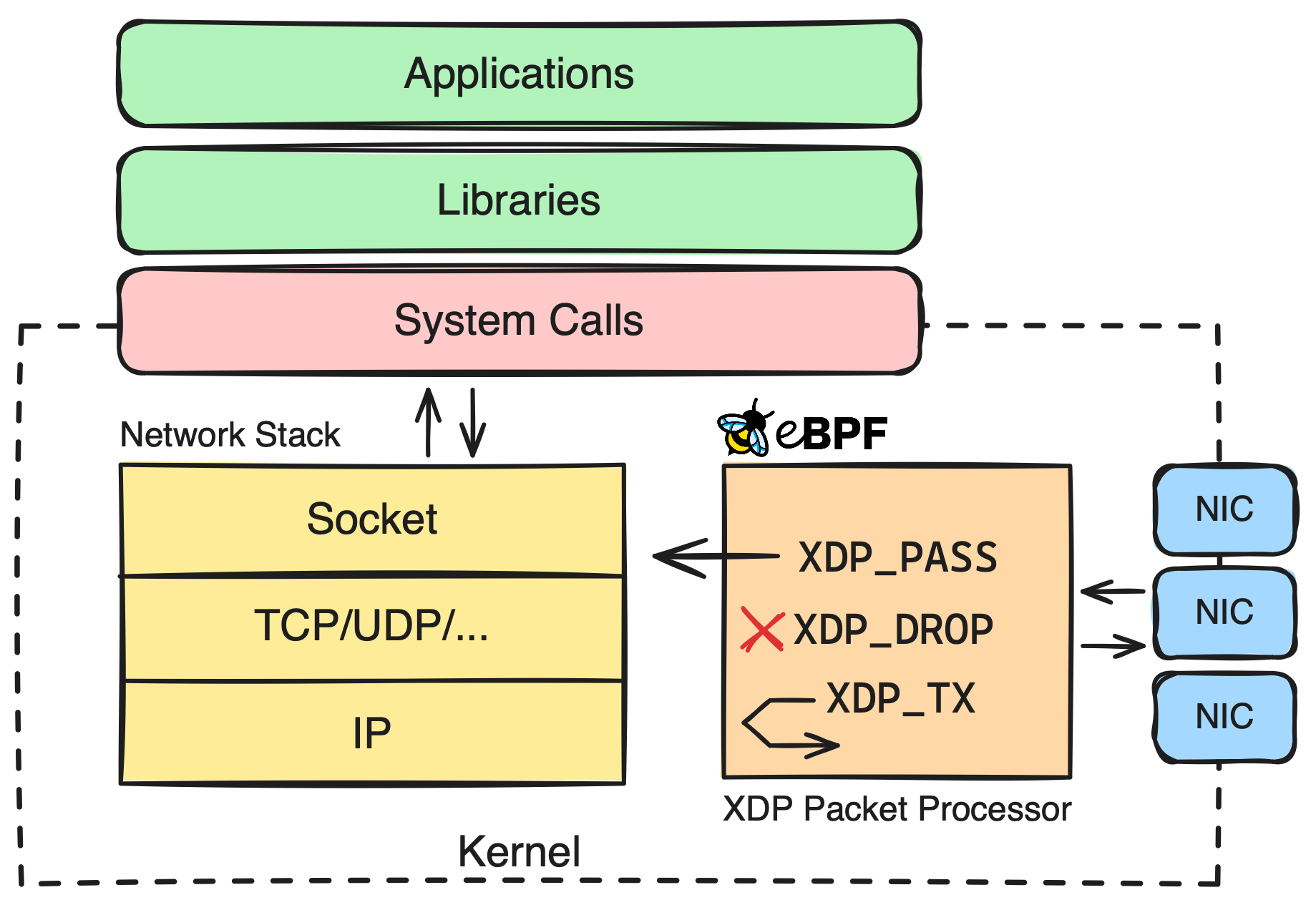
编写 eBPF 程序
我们将编写一个 eBPF 程序,根据源 IP 地址和端口号来计算传入 IP 数据包的数量,然后从用户空间中的 BPF Map中读取计数。我们将解析每个数据包的以太网、IP 和 TCP/UDP 标头,并将有效 TCP/UDP 数据包的计数存储在 BPF Map中。
一、eBPF程序:
// hello_ebpf.c
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
#define MAX_MAP_ENTRIES 100
/* Define an LRU hash map for storing packet count by source IP and port */
struct {
__uint(type, BPF_MAP_TYPE_LRU_HASH);
__uint(max_entries, MAX_MAP_ENTRIES);
__type(key, u64); // source IPv4 addresses and port tuple
__type(value, u32); // packet count
} xdp_stats_map SEC(".maps");与第一个示例一样,我们将包含 vmlinux.h 和 BPF 辅助标头。我们还定义了一个Map xdp_stats_map 来存储 IP:ports 和数据包计数信息。然后,我们将在钩子函数内填充此Map并读取用户空间程序中的内容。
我所说的 IP:ports 基本上是一个 u64 值,包含源 IP、源端口和目标端口。 IP 地址(特别是 IPv4)是 32 位长,每个端口号是 16 位长,因此我们需要 64 位来存储所有三个 – 这就是我们在这里使用 u64 的原因。我们在这里只处理入口(传入数据包),因此不需要存储目标 IP 地址。
与上一个示例不同,我们现在使用 BPF_MAP_TYPE_LRU_HASH 作为map类型。这种类型的Map允许我们将 (key, value) 对存储为具有 LRU 变体的哈希Map。
看看我们如何在这里定义Map,我们显式设置了最大条目数以及Map键和值的类型。对于键,我们使用 64 位无符号整数,对于值,我们使用 32 位无符号整数。
u32的最大值是2^32 - 1,对于本示例而言,这已经足够了。
要了解 IP 地址和端口号,我们首先需要解析数据包并读取以太网、IP 和 TCP/UDP 标头。
由于 XDP 放置在网络接口卡之后,我们将获得以字节为单位的原始数据包数据,因此我们需要手动遍历字节数组并解组以太网、IP 和 TCP/UDP 标头。
希望我们在( vmlinux.h 、 struct iphdr 、 struct tcphdr 和 struct udphdr ) > 头文件。我们将使用这些结构在单独的函数 parse_ip_packet 中提取 IP 地址和端口号信息:
// hello_ebpf.c
#define ETH_P_IP 0x0800 /* Internet Protocol packet */
#define PARSE_SKIP 0
#define PARSED_TCP_PACKET 1
#define PARSED_UDP_PACKET 2
static __always_inline int parse_ip_packet(struct xdp_md *ctx, u64 *ip_metadata) {
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
// First, parse the ethernet header.
struct ethhdr *eth = data;
if ((void *)(eth + 1) > data_end) {
return PARSE_SKIP;
}
if (eth->h_proto != bpf_htons(ETH_P_IP)) {
// The protocol is not IPv4, so we can't parse an IPv4 source address.
return PARSE_SKIP;
}
// Then parse the IP header.
struct iphdr *ip = (void *)(eth + 1);
if ((void *)(ip + 1) > data_end) {
return PARSE_SKIP;
}
u16 src_port, dest_port;
int retval;
if (ip->protocol == IPPROTO_TCP) {
struct tcphdr *tcp = (void*)ip + sizeof(*ip);
if ((void*)(tcp+1) > data_end) {
return PARSE_SKIP;
}
src_port = bpf_ntohs(tcp->source);
dest_port = bpf_ntohs(tcp->dest);
retval = PARSED_TCP_PACKET;
} else if (ip->protocol == IPPROTO_UDP) {
struct udphdr *udp = (void*)ip + sizeof(*ip);
if ((void*)(udp+1) > data_end) {
return PARSE_SKIP;
}
src_port = bpf_ntohs(udp->source);
dest_port = bpf_ntohs(udp->dest);
retval = PARSED_UDP_PACKET;
} else {
// The protocol is not TCP or UDP, so we can't parse a source port.
return PARSE_SKIP;
}
// Return the (source IP, destination IP) tuple in network byte order.
// |<-- Source IP: 32 bits -->|<-- Source Port: 16 bits --><-- Dest Port: 16 bits -->|
*ip_metadata = ((u64)(ip->saddr) << 32) | ((u64)src_port << 16) | (u64)dest_port;
return retval;
}函数::
- 检查数据包是否具有有效的以太网标头、IP 标头以及 TCP 或 UDP 标头。这些检查是通过使用
struct ethhdr的h_proto和struct iphdr的protocol完成的。每个标头都存储它所包装的内部数据包的协议。 - 从 IP 标头中提取 IP 地址,从 TCP/UDP 标头中提取端口号,并在 64 位无符号整数 (
u64) 内形成IP:ports元组 - 返回一个代码来告诉调用者该数据包是 TCP 数据包、UDP 数据包还是其他 (
PARSE_SKIP)
请注意函数签名开头的 __always_inline 。这告诉编译器始终将此函数内联为静态代码,这使我们免于执行函数调用。
现在是时候编写钩子函数并使用 parse_ip_packet :
// hello_ebpf.c
SEC("xdp")
int xdp_prog_func(struct xdp_md *ctx) {
u64 ip_meta;
int retval = parse_ip_packet(ctx, &ip_meta);
if (retval != PARSED_TCP_PACKET) {
return XDP_PASS;
}
u32 *pkt_count = bpf_map_lookup_elem(&xdp_stats_map, &ip_meta);
if (!pkt_count) {
// No entry in the map for this IP tuple yet, so set the initial value to 1.
u32 init_pkt_count = 1;
bpf_map_update_elem(&xdp_stats_map, &ip_meta, &init_pkt_count, BPF_ANY);
} else {
// Entry already exists for this IP tuple,
// so increment it atomically.
__sync_fetch_and_add(pkt_count, 1);
}
return XDP_PASS;
}The xdp_prog_func is fairly simple as we already coded most of the program logic inside parse_ip_packet. What we do here is:
xdp_prog_func 相当简单,因为我们已经在 parse_ip_packet 内编写了大部分程序逻辑。我们在这里所做的是:
- 使用
parse_ip_packet解析数据包 - 如果不是 TCP 或 UDP 数据包,则返回
XDP_PASS跳过计数 - 使用
bpf_map_lookup_elem辅助函数在 BPF Map键中查找IP:ports元组 - 如果第一次看到
IP:ports元组,则将该值设置为 1,否则将其增加 1。__sync_fetch_and_add是这里内置的 LLVM
最后,我们使用 SEC("xdp") 宏将此函数附加到 XDP 子系统。
编写用户空间程序
是时候再次深入研究 Go 代码了。
// main.go
//go:generate go run github.com/cilium/ebpf/cmd/bpf2go ebpf xdp.c
var (
ifaceName = flag.String("iface", "", "network interface to attach XDP program to")
)
func main() {
log.SetPrefix("packet_count: ")
log.SetFlags(log.Ltime | log.Lshortfile)
flag.Parse()
// Subscribe to signals for terminating the program.
stop := make(chan os.Signal, 1)
signal.Notify(stop, os.Interrupt, syscall.SIGTERM)
iface, err := net.InterfaceByName(*ifaceName)
if err != nil {
log.Fatalf("network iface lookup for %q: %s", *ifaceName, err)
}
// Load pre-compiled programs and maps into the kernel.
objs := ebpfObjects{}
if err := loadEbpfObjects(&objs, nil); err != nil {
log.Fatalf("loading objects: %v", err)
}
defer objs.Close()
// Attach the program.
l, err := link.AttachXDP(link.XDPOptions{
Program: objs.XdpProgFunc,
Interface: iface.Index,
})
if err != nil {
log.Fatalf("could not attach XDP program: %s", err)
}
defer l.Close()
log.Printf("Attached XDP program to iface %q (index %d)", iface.Name, iface.Index)这里我们首先加载生成的 eBPF 程序并使用 loadEbpfObjects 函数进行Map。然后我们使用 link.AttachXDP 函数将程序附加到指定的网络接口。与前面的示例类似,我们使用通道来监听中断信号并优雅地关闭程序。
接下来,我们将每秒读取map内容并将数据包计数打印到标准输出:
// main.go
// ...
ticker := time.NewTicker(time.Second)
defer ticker.Stop()
for {
select {
case <-stop:
if err := objs.XdpStatsMap.Close(); err != nil {
log.Fatalf("closing map reader: %s", err)
}
return
case <-ticker.C:
m, err := parsePacketCounts(objs.XdpStatsMap, excludeIPs)
if err != nil {
log.Printf("Error reading map: %s", err)
continue
}
log.Printf("Map contents:\n%s", m)
srv.Submit(m)
}
}
}我们将使用实用函数 parsePacketCounts 来读取map内容并解析数据包计数。该函数将循环读取map内容。
由于我们将从Map中获得原始字节,因此我们需要解析这些字节并将其转换为人类可读的格式。我们将定义一个新类型 PacketCounts 来存储解析后的map内容。
// main.go
type IPMetadata struct {
SrcIP netip.Addr
SrcPort uint16
DstPort uint16
}
func (t *IPMetadata) UnmarshalBinary(data []byte) (err error) {
if len(data) != 8 {
return fmt.Errorf("invalid data length: %d", len(data))
}
if err = t.SrcIP.UnmarshalBinary(data[4:8]); err != nil {
return
}
t.SrcPort = uint16(data[3])<<8 | uint16(data[2])
t.DstPort = uint16(data[1])<<8 | uint16(data[0])
return nil
}
func (t IPMetadata) String() string {
return fmt.Sprintf("%s:%d => :%d", t.SrcIP, t.SrcPort, t.DstPort)
}
type PacketCounts map[string]int
func (i PacketCounts) String() string {
var keys []string
for k := range i {
keys = append(keys, k)
}
sort.Strings(keys)
var sb strings.Builder
for _, k := range keys {
sb.WriteString(fmt.Sprintf("%s\t| %d\n", k, i[k]))
}
return sb.String()
}我们定义了一个新类型 IPMetadata 来存储 IP:ports 元组。我们还定义了一个 UnmarshalBinary 方法来解析原始字节并将其转换为人类可读的格式。我们还定义了一个 String 方法来以人类可读的格式打印 IP:ports 元组。
然后我们定义了一个新类型 PacketCounts 来存储解析后的map内容。我们还定义了一个 String 方法来以人类可读的格式打印map内容。
最后,我们将使用 PacketCounts 类型来解析map内容并打印数据包计数:
// main.go
func parsePacketCounts(m *ebpf.Map, excludeIPs map[string]bool) (PacketCounts, error) {
var (
key IPMetadata
val uint32
counts = make(PacketCounts)
)
iter := m.Iterate()
for iter.Next(&key, &val) {
if _, ok := excludeIPs[key.SrcIP.String()]; ok {
continue
}
counts[key.String()] = int(val)
}
return counts, iter.Err()
}运行程序
我们首先需要编译eBPF程序,然后运行用户空间程序。
$ go generate
Compiled /Users/sazak/workspace/gocode/src/github.com/ozansz/intro-ebpf-with-go/0x03-packet-count/ebpf_bpfel.o
Stripped /Users/sazak/workspace/gocode/src/github.com/ozansz/intro-ebpf-with-go/0x03-packet-count/ebpf_bpfel.o
Wrote /Users/sazak/workspace/gocode/src/github.com/ozansz/intro-ebpf-with-go/0x03-packet-count/ebpf_bpfel.go
Compiled /Users/sazak/workspace/gocode/src/github.com/ozansz/intro-ebpf-with-go/0x03-packet-count/ebpf_bpfeb.o
Stripped /Users/sazak/workspace/gocode/src/github.com/ozansz/intro-ebpf-with-go/0x03-packet-count/ebpf_bpfeb.o
Wrote /Users/sazak/workspace/gocode/src/github.com/ozansz/intro-ebpf-with-go/0x03-packet-count/ebpf_bpfeb.go
$ go build -o packet_count现在我们可以运行它:
$ sudo ./packet_count --iface eth0
packet_count: 22:11:10 main.go:107: Attached XDP program to iface "eth0" (index 2)
packet_count: 22:11:10 main.go:132: Map contents:
192.168.5.2:58597 => :22 | 51
packet_count: 22:11:11 main.go:132: Map contents:
192.168.5.2:58597 => :22 | 52
packet_count: 22:11:11 main.go:132: Map contents:
192.168.5.2:58597 => :22 | 53从 IP 地址 192.168.5.2 到达端口 22 的数据包是 SSH 数据包,因为我在虚拟机内运行此程序并且通过 SSH 连接。
让我们在另一个终端的虚拟机内运行 curl ,看看会发生什么:
$ curl https://www.google.com/同时在第一个终端中:
packet_count: 22:14:07 main.go:132: Map contents:
172.217.22.36:443 => :38324 | 12
192.168.5.2:58597 => :22 | 551
packet_count: 22:14:08 main.go:132: Map contents:
172.217.22.36:443 => :38324 | 12
192.168.5.2:58597 => :22 | 552
packet_count: 22:14:08 main.go:132: Map contents:
172.217.22.36:443 => :38324 | 30
192.168.5.2:58597 => :22 | 570
1packet_count: 22:14:09 main.go:132: Map contents:
172.217.22.36:443 => :38324 | 30
192.168.5.2:58597 => :22 | 571我们看到从 IP 地址 172.217.22.36 到达端口 38324 的数据包是来自 curl 命令的数据包。
结论
eBPF 在很多方面都很强大,我认为这是一项值得投入时间的好技术,特别是在系统编程、可观察性或安全性方面。在本文中,我们了解了 eBPF 是什么、它是如何工作的以及如何开始在 Go 中使用它。
我希望您喜欢这篇文章并学到一些新东西。如果您有任何疑问,请随时oznszk。
 CFC4N的博客 由 CFC4N 创作,采用 署名—非商业性使用—相同方式共享 4.0 进行许可。基于https://www.cnxct.com上的作品创作。转载请注明转自:eBPF在Golang中的应用介绍
CFC4N的博客 由 CFC4N 创作,采用 署名—非商业性使用—相同方式共享 4.0 进行许可。基于https://www.cnxct.com上的作品创作。转载请注明转自:eBPF在Golang中的应用介绍